IROS 2026 SUBMISSION
Truncated Diffusion Process for Temporal Consistent Inference
Imagine a robot following a person down a hallway. It needs a new prediction of where the person is headed, every fraction of a second. A diffusion model can make that prediction — but only after many slow denoising steps, repeated from scratch, every single time.
Diffusion models are strong — but slow
Diffusion models are good at predicting human motion. The future is not one path, it's many. A person walking toward a junction might turn left, turn right, or keep going straight. Diffusion models can represent all of these possibilities at once, instead of collapsing them into one average guess.

The problem is speed. A diffusion model starts from pure noise and removes it step by step, often 100 steps, to produce a single prediction. Some methods try to skip steps to go faster. But they either lose sample quality, or they are still too slow for real time.
We already have a prior — we were just throwing it away
Robots don't predict once. They predict again and again, every frame. Before each new prediction, we already have a set of samples from one moment ago. The person has barely moved since then, so those old samples should still be close to what we want now.
We can treat them as a prior: a good starting guess, instead of pure noise. This is not a new trick — image inpainting and super-resolution already use priors this way. We bring the same idea to human trajectory prediction, where a prior naturally exists at every step, and the standard recipe was throwing it away.
Our idea, in two steps
Instead of resetting to pure noise every frame, we reuse last frame's samples and only re-denoise as much as the new information requires:
- Take last frame's samples and add back only part of the noise, just enough to reach an intermediate noise level.
- Denoise from there using the current frame's new conditioning.
Because we skip most of the early denoising steps, we call this a truncated diffusion process. In our experiments, full diffusion uses 100 steps; truncated diffusion runs with ratios 0.75, 0.50, 0.20, 0.05 of that, i.e. 75, 50, 20, or just 5 denoising steps.
A 1D mixture-of-Gaussians toy example — the standard diffusion process: denoising trajectories starting from pure noise $p_\text{noise}(\mathbf{x})$ converge early, then split apart into the two modes of $p_\text{data}(\mathbf{x})$ only in the last few steps. (Animation from the supplementary material.)
Our truncated process: start from a previous sample (one Gaussian mode of $p_\text{noise}(\mathbf{x})$), add back partial noise to reach an intermediate level $p_{t=0.15}(\mathbf{x})$, then denoise with the new condition to land on a new sample of $p_\text{data}(\mathbf{x})$.
The toy example above is what convinced us this should work. Watch the denoising trajectories in the first figure: paths that start from very different noise samples all converge toward each other early in denoising, and only pull apart into distinct modes in the last few steps. In other words, most of the early steps are doing the same generic work regardless of where you started — it's only the tail end of denoising that decides which mode you land in. If we already have a reasonable sample sitting near a plausible mode, we don't need to redo that generic early work at all.
One challenge: the world keeps changing
There's a catch with reusing old samples. The conditioning — the scene, the person's recent motion — keeps changing from frame to frame. Small errors from that change could build up over time.
So we worked out a bound. It says the error of our truncated process, compared to full diffusion, is controlled by exactly two things: how much the conditioning changed, and how much noise we add back before re-denoising (the truncation ratio).
$$D_{KL}(Q \parallel p_{c_1}) \leq \bar{\alpha}_k \cdot D_{KL}(p_{c_0} \parallel p_{c_1})$$
Read informally: if the world barely changed since the last frame, the bound is small, and we can get away with very few denoising steps. If something changed a lot — the person suddenly stopped or turned sharply — the bound loosens, and we should fall back toward more steps, up to full diffusion in the extreme case. The truncation ratio is the knob that controls this trade-off.
Does it actually work?
We tested on two long-horizon human trajectory datasets: GTA-IM (simulation) and HPS (real world), predicting 3 seconds of future 2D motion from 5 seconds of history and a local occupancy map.
Full diffusion uses 100 denoising steps. Our method reaches comparable — sometimes better — accuracy using only a fraction of those steps, and it beats DDIM, the standard fast-sampling baseline, at matched step counts. Below we show what that looks like qualitatively; for the full numbers (1-minADE, k-minADE, FDE across both datasets and baselines), see Table I in the paper.
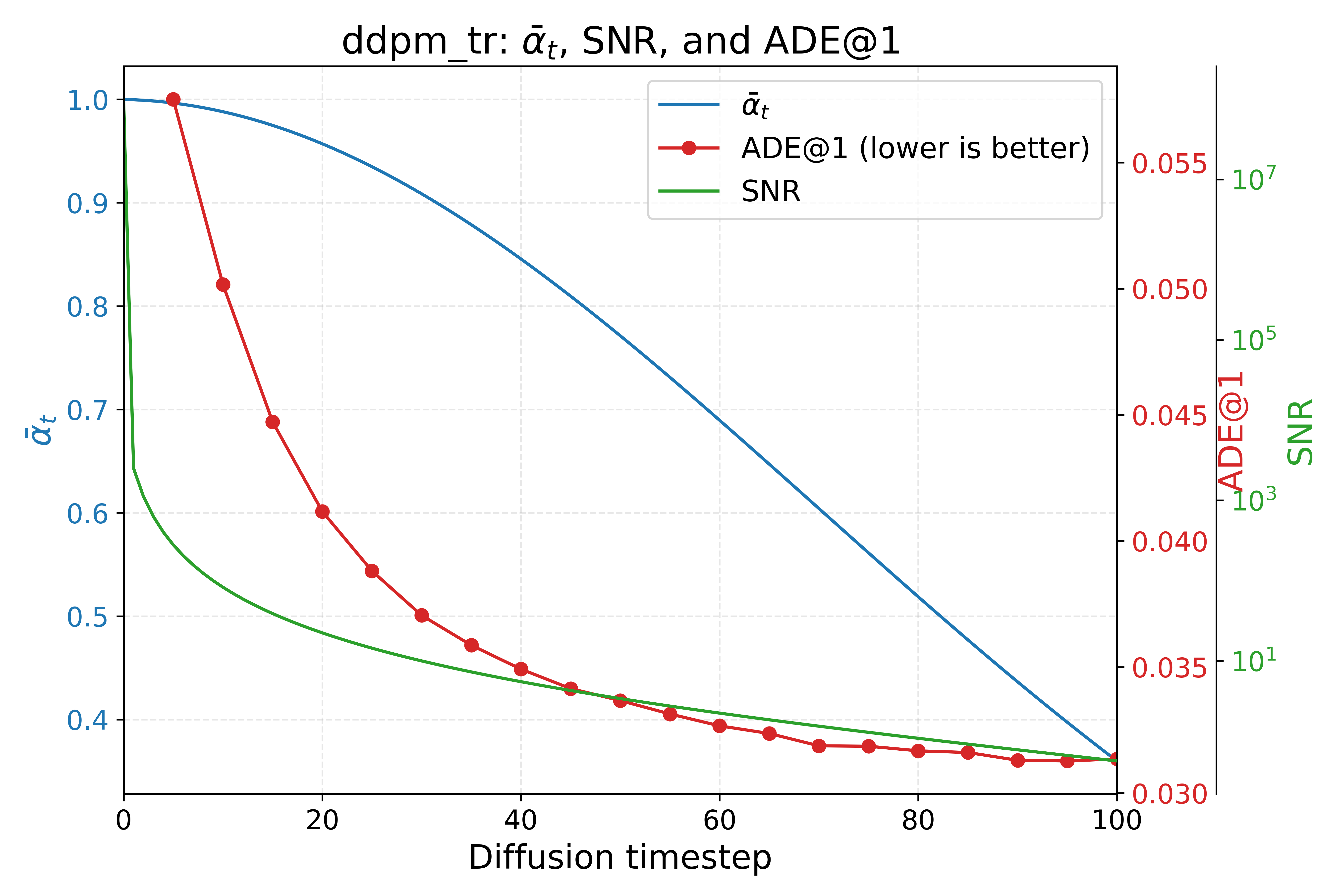
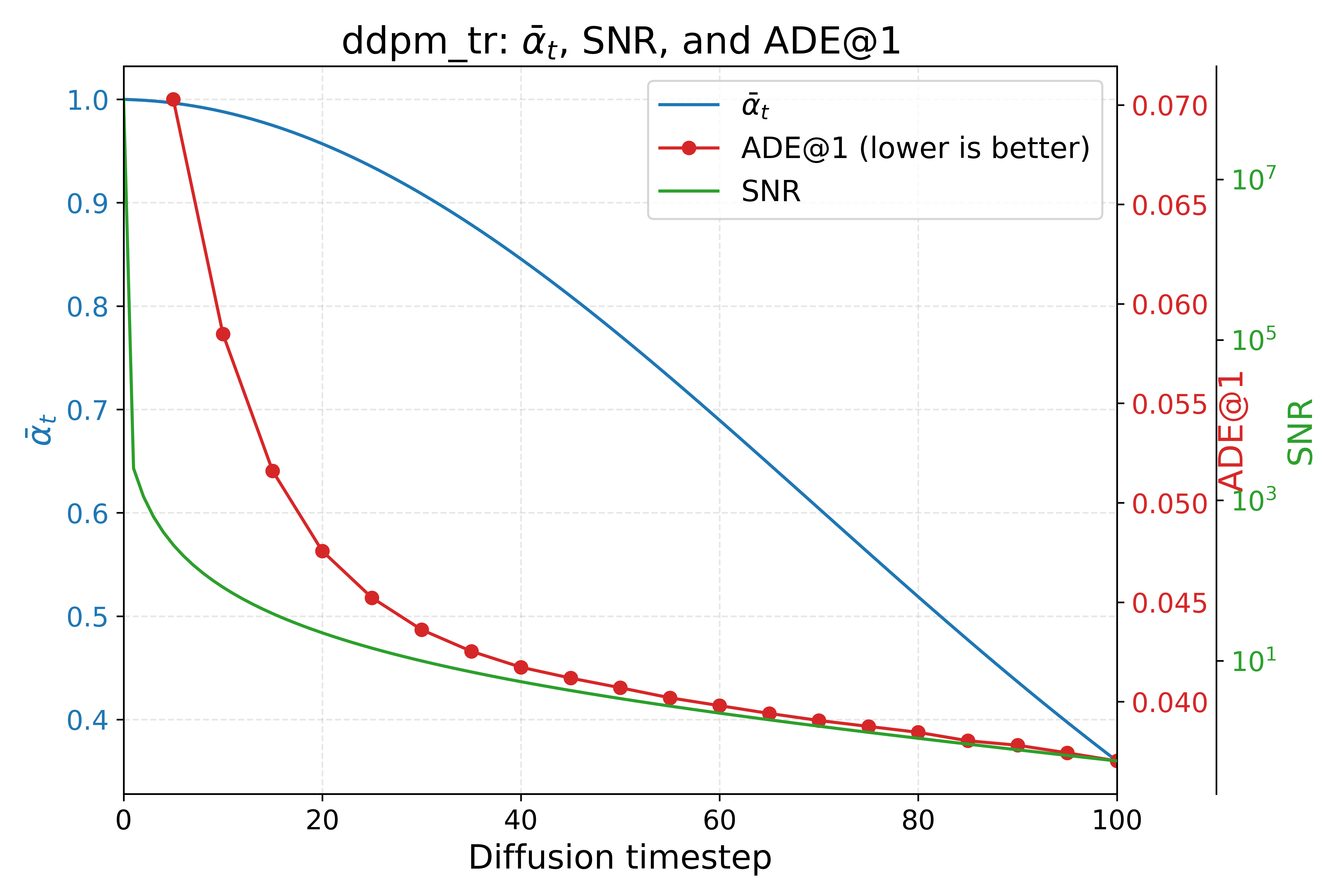
How far can we push the truncation?
We swept the truncation ratio all the way from 0.05 to 1.0 (full diffusion) and tracked how sampling quality changes alongside the noise scheduler's signal-to-noise ratio (SNR). The pattern is exactly what the theory predicts: quality degrades gradually, not suddenly, and it tracks the SNR curve closely — fewer steps means a lower SNR at the point we start denoising, which means a slightly noisier answer, in a smooth and predictable way rather than a cliff.
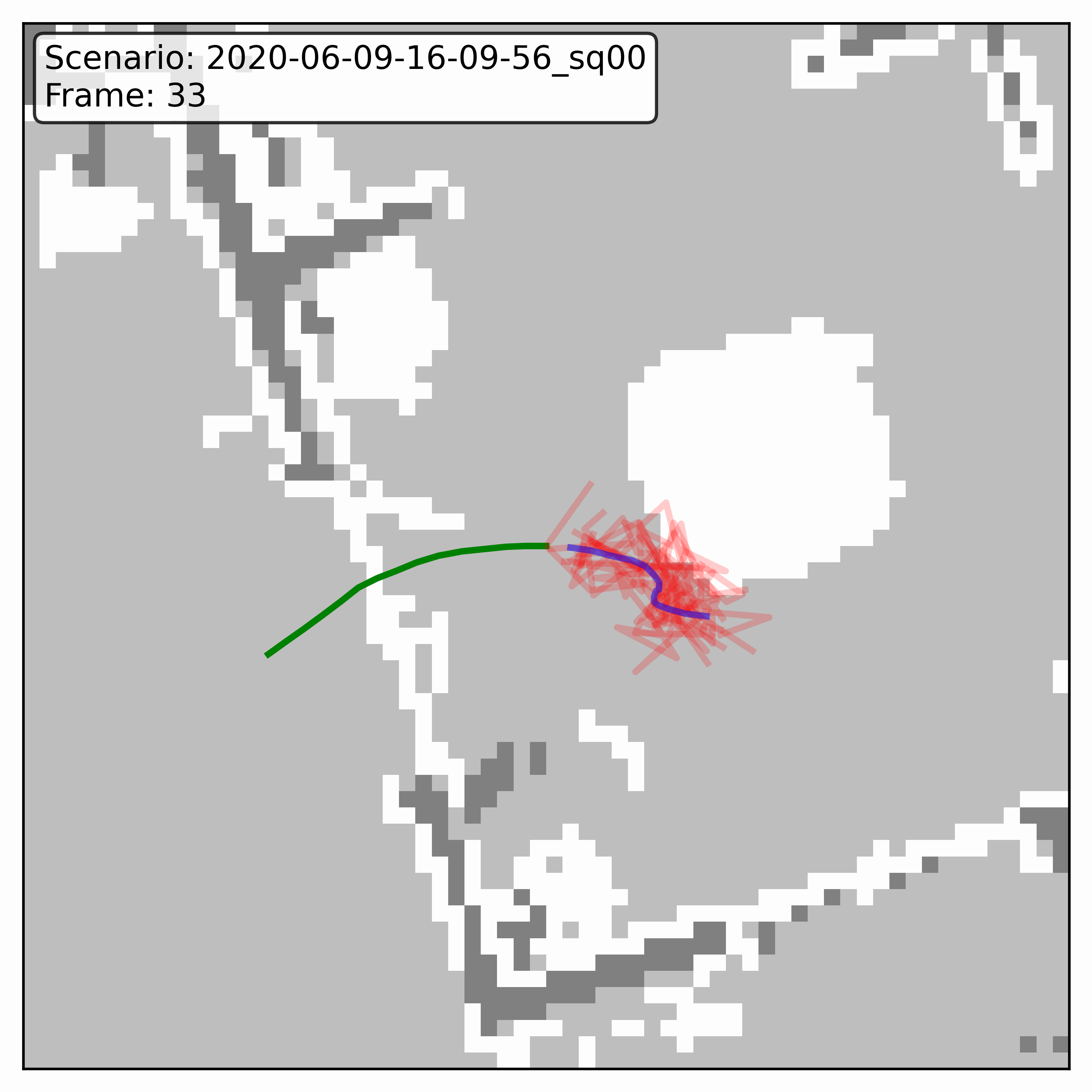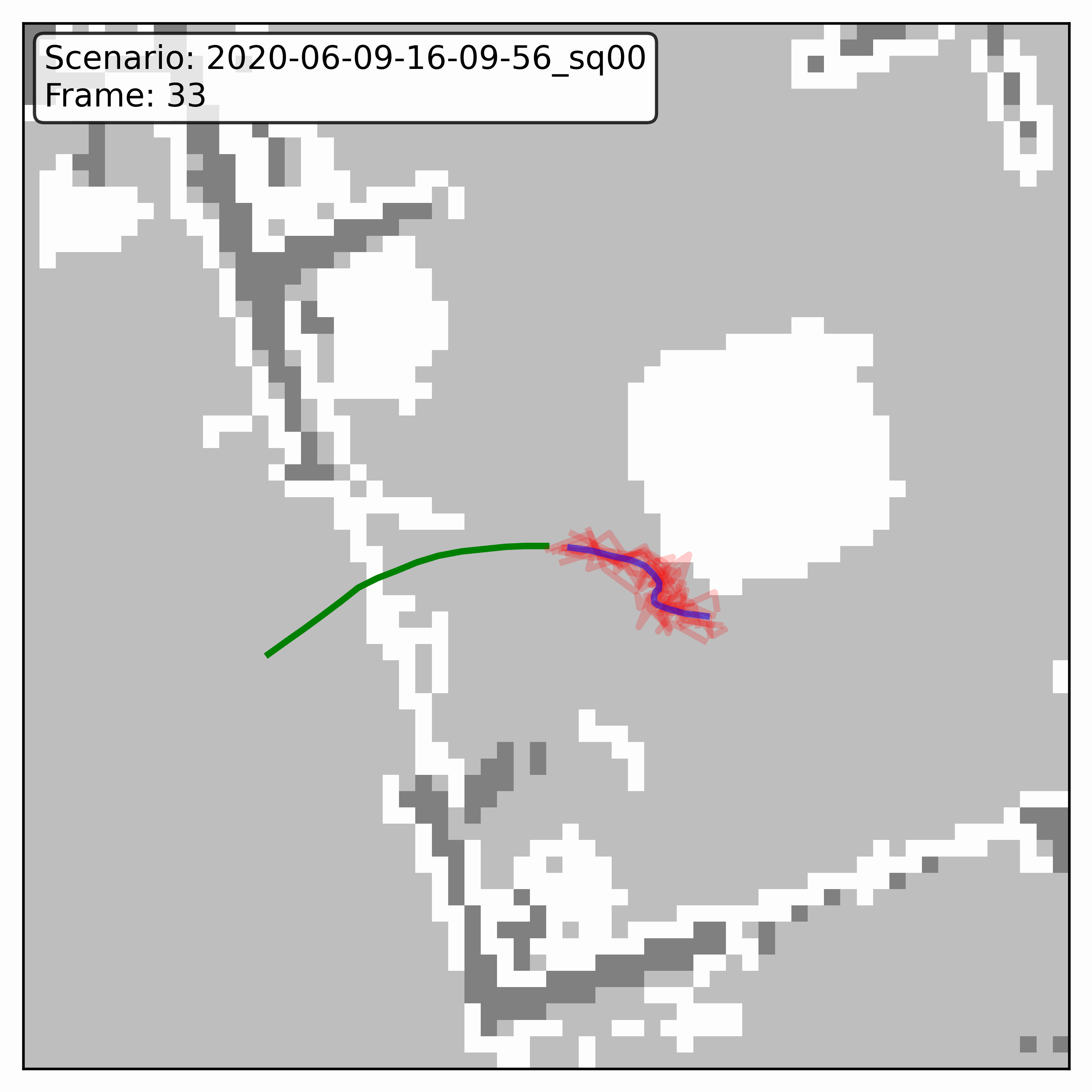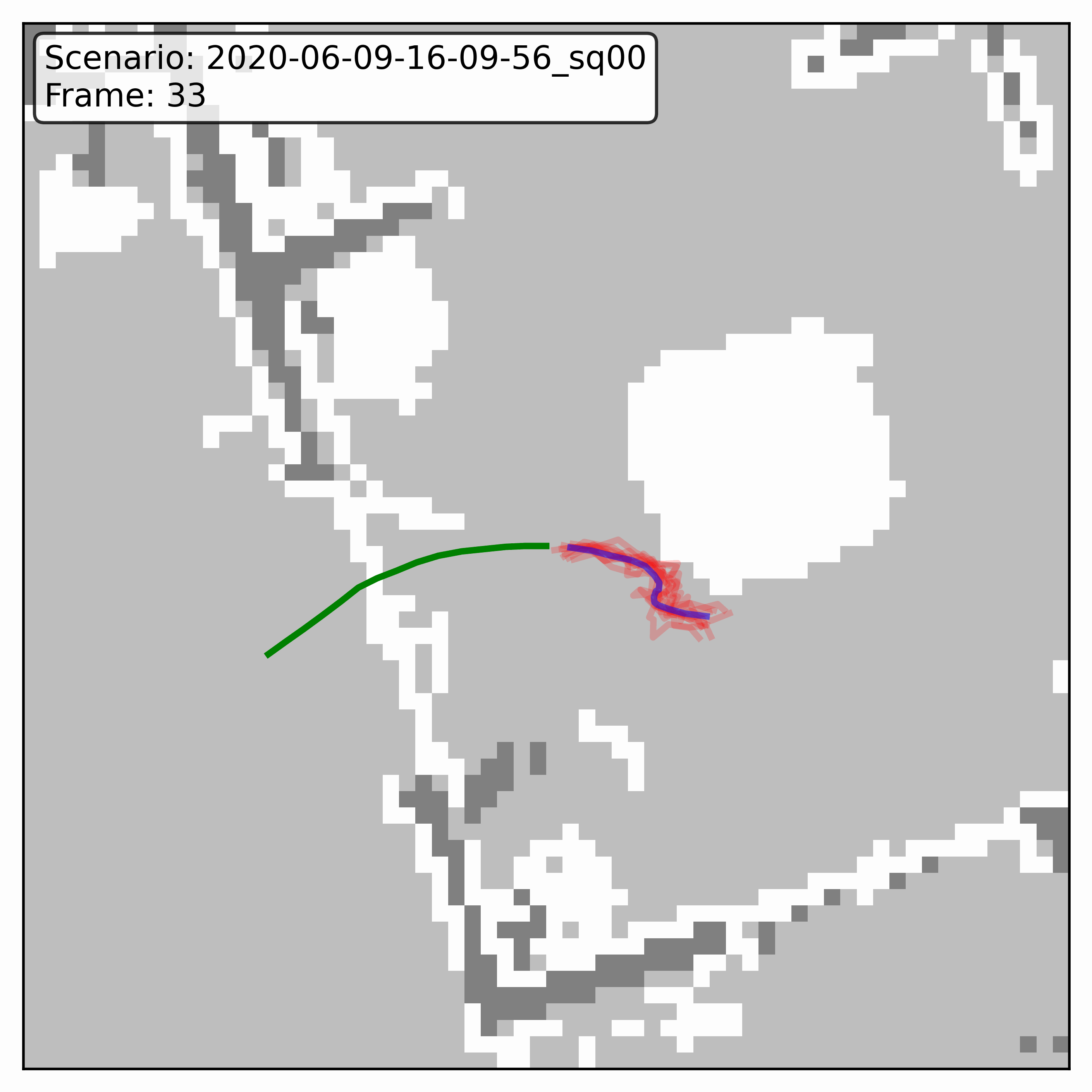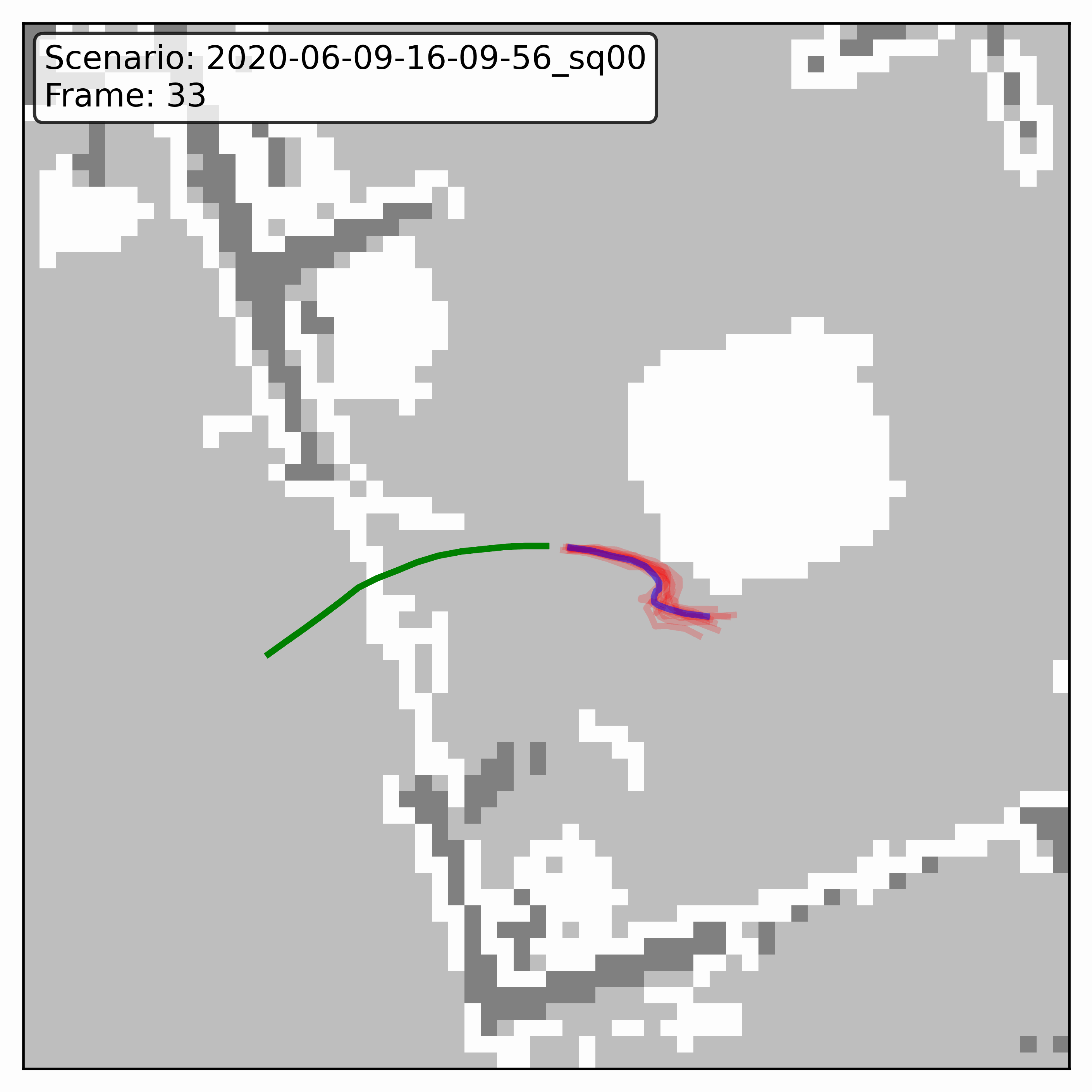
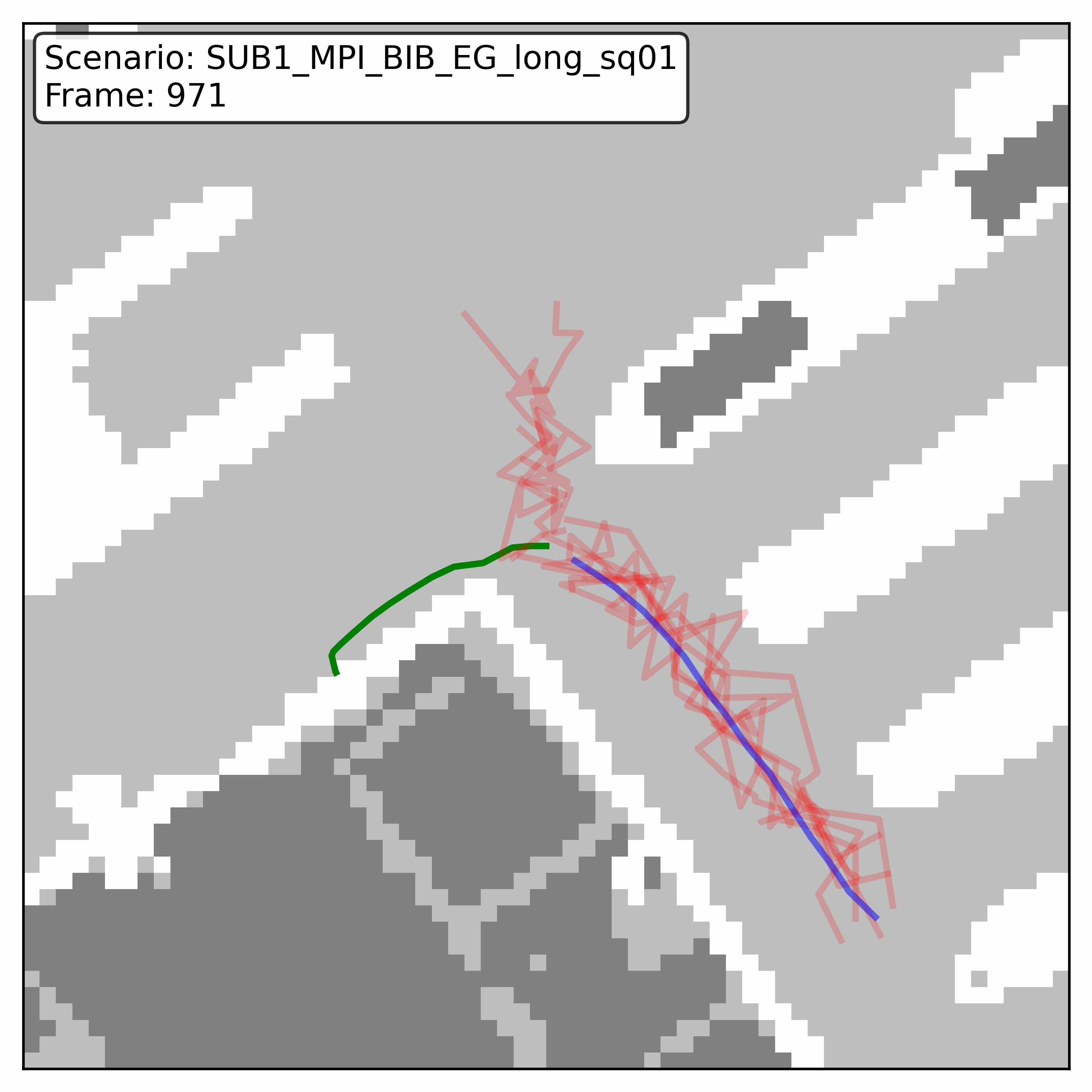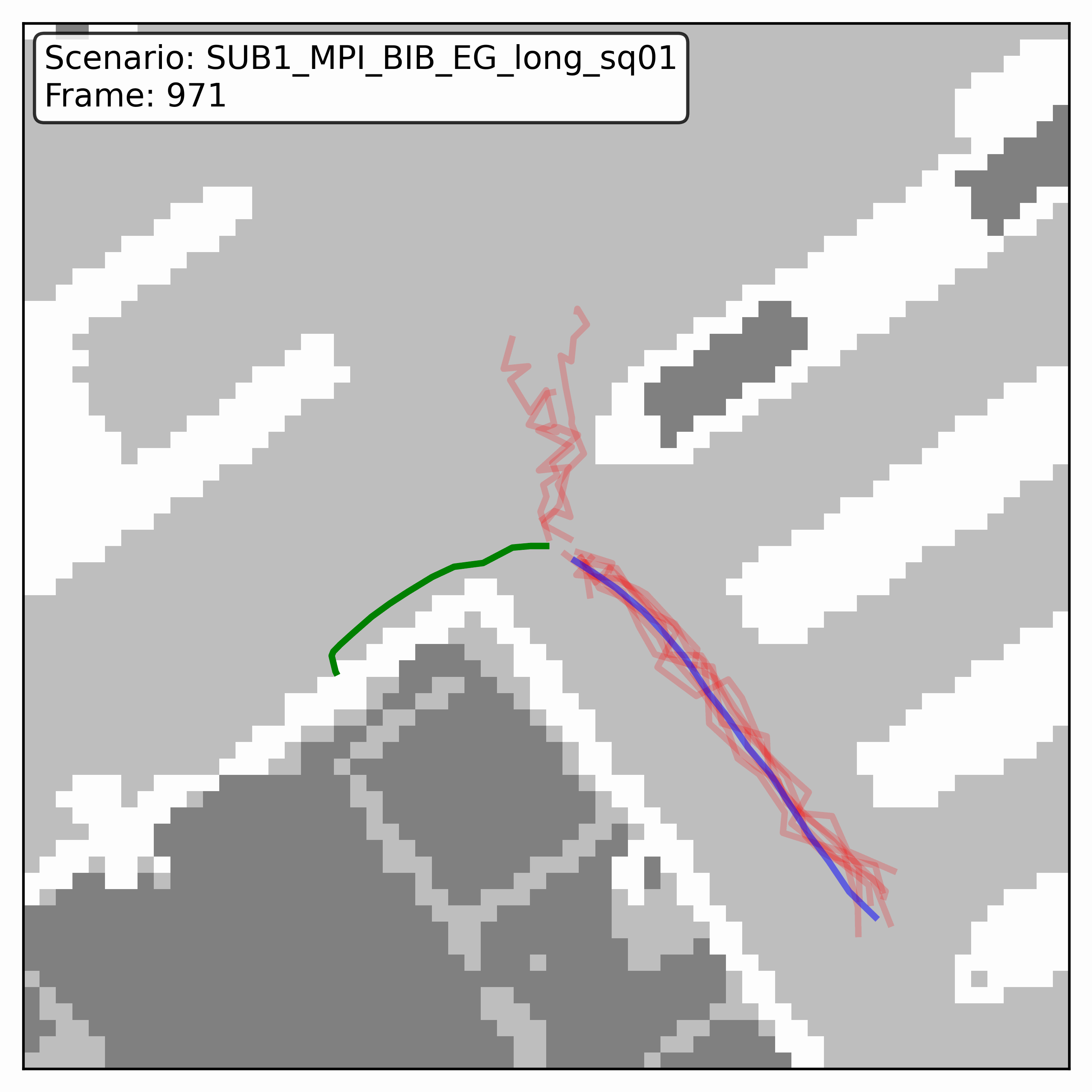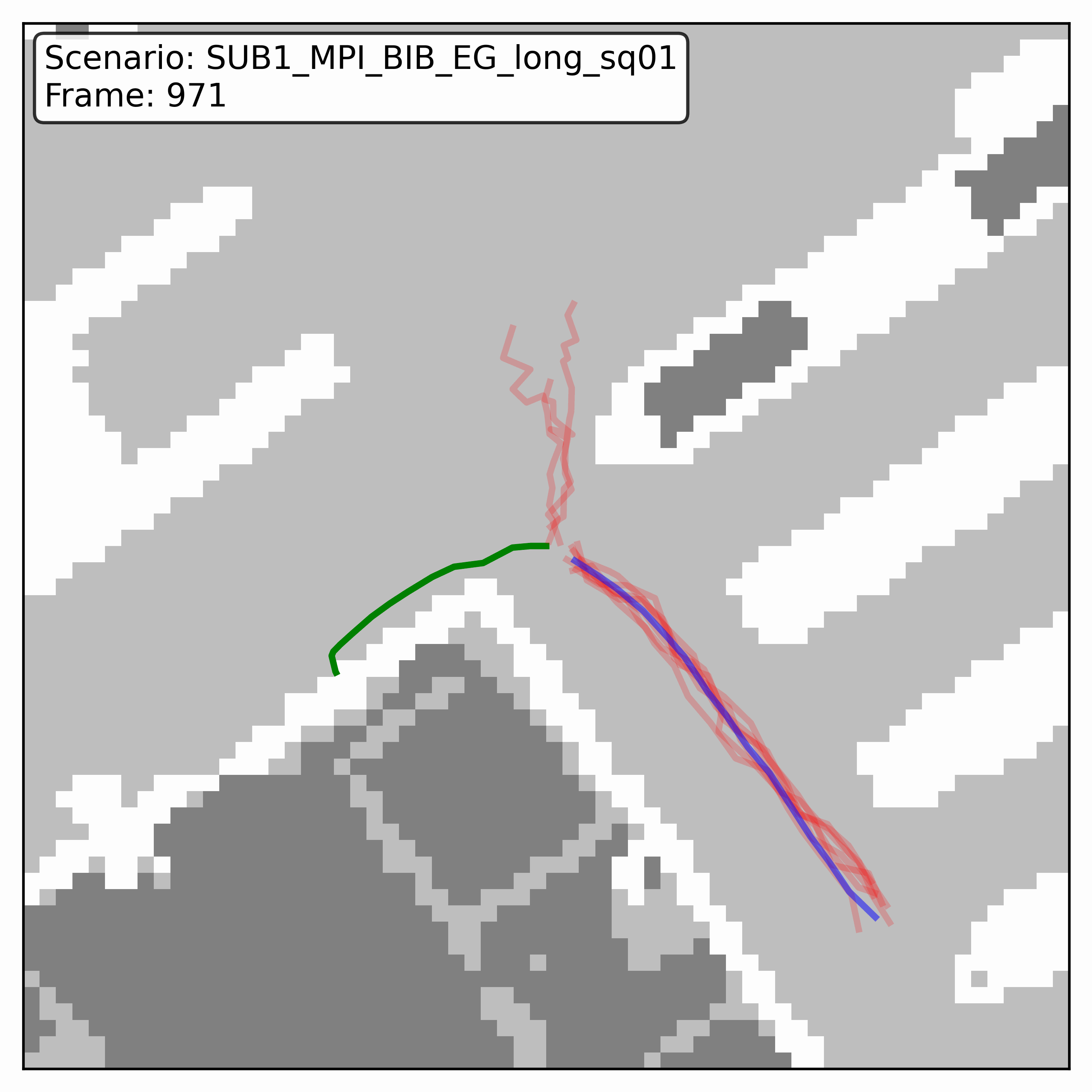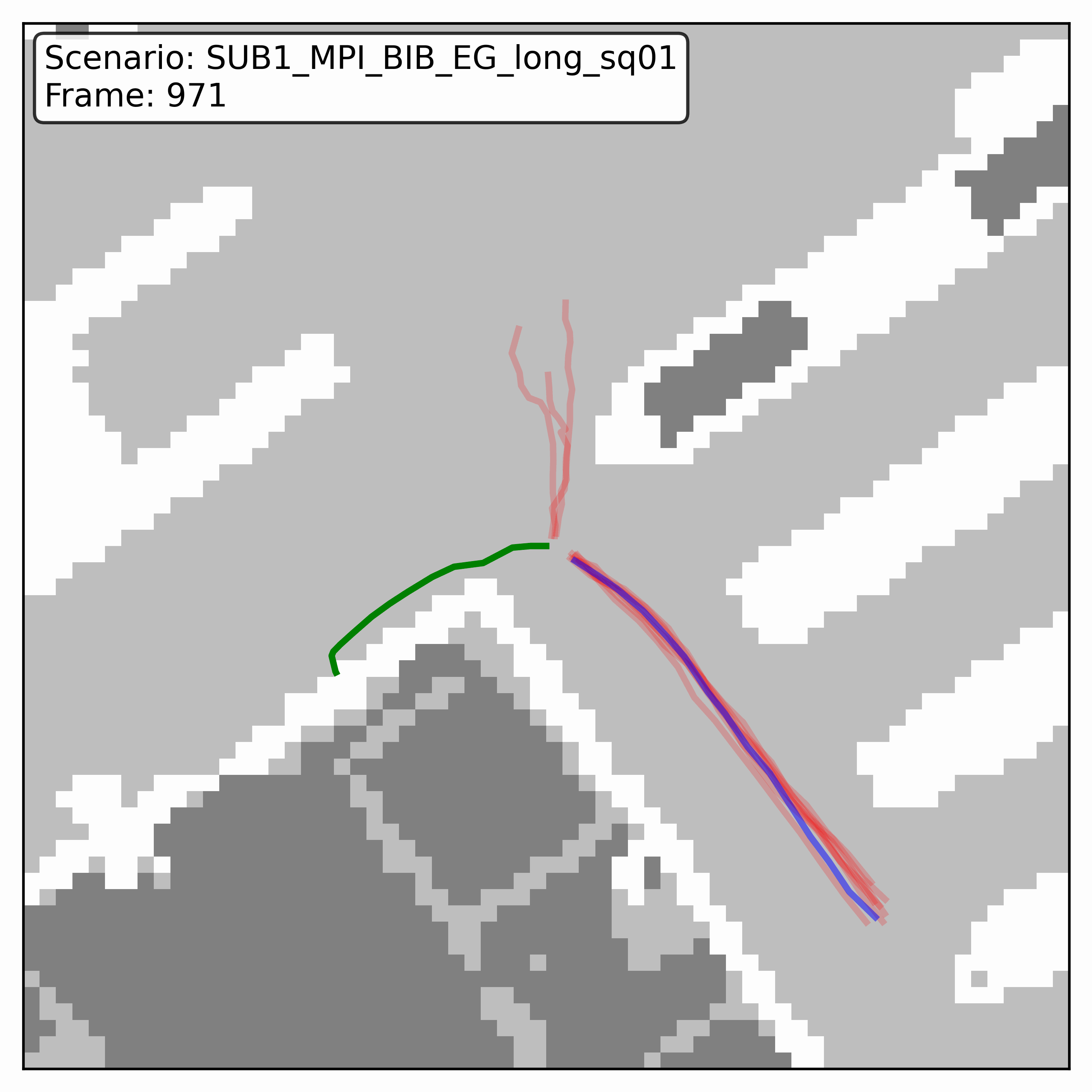
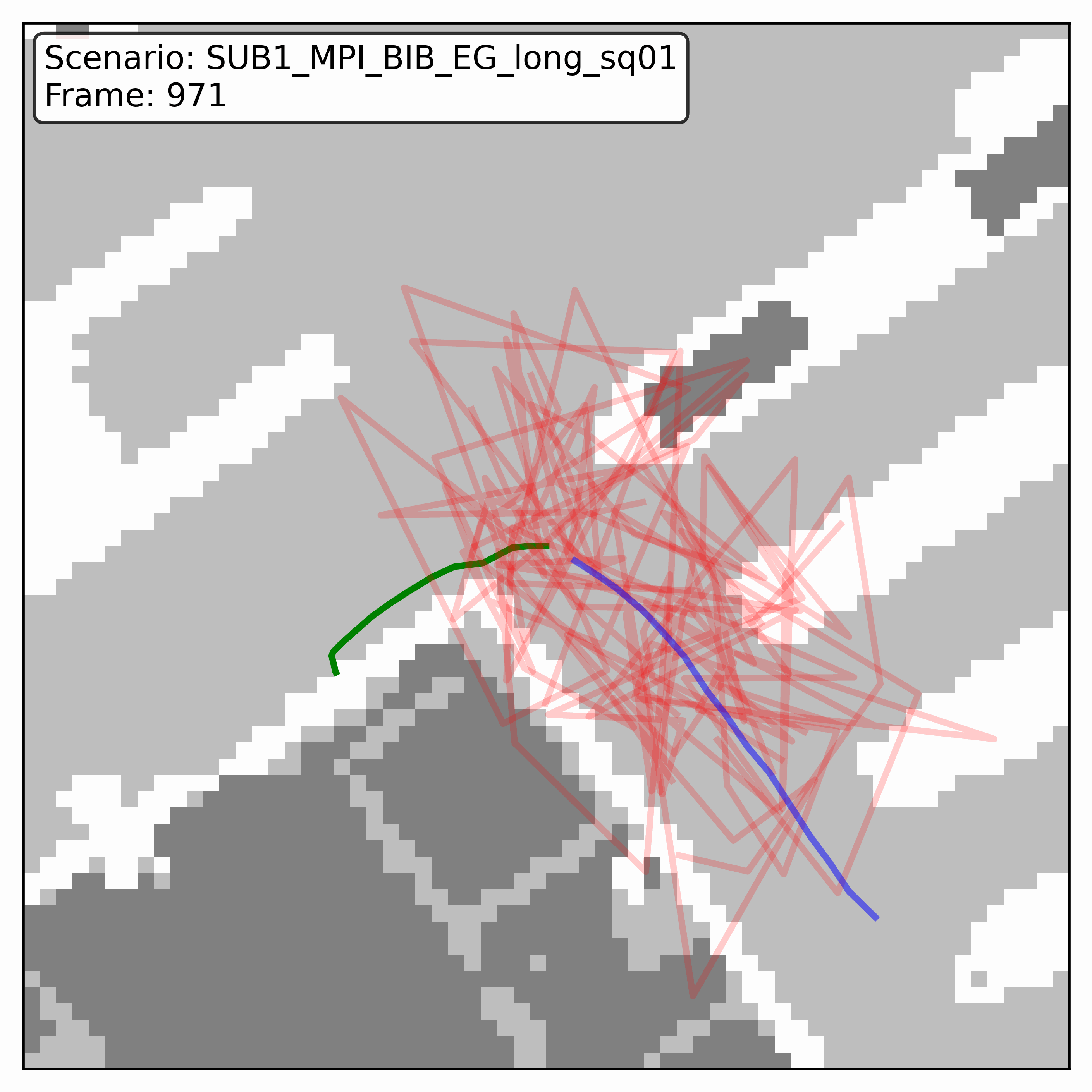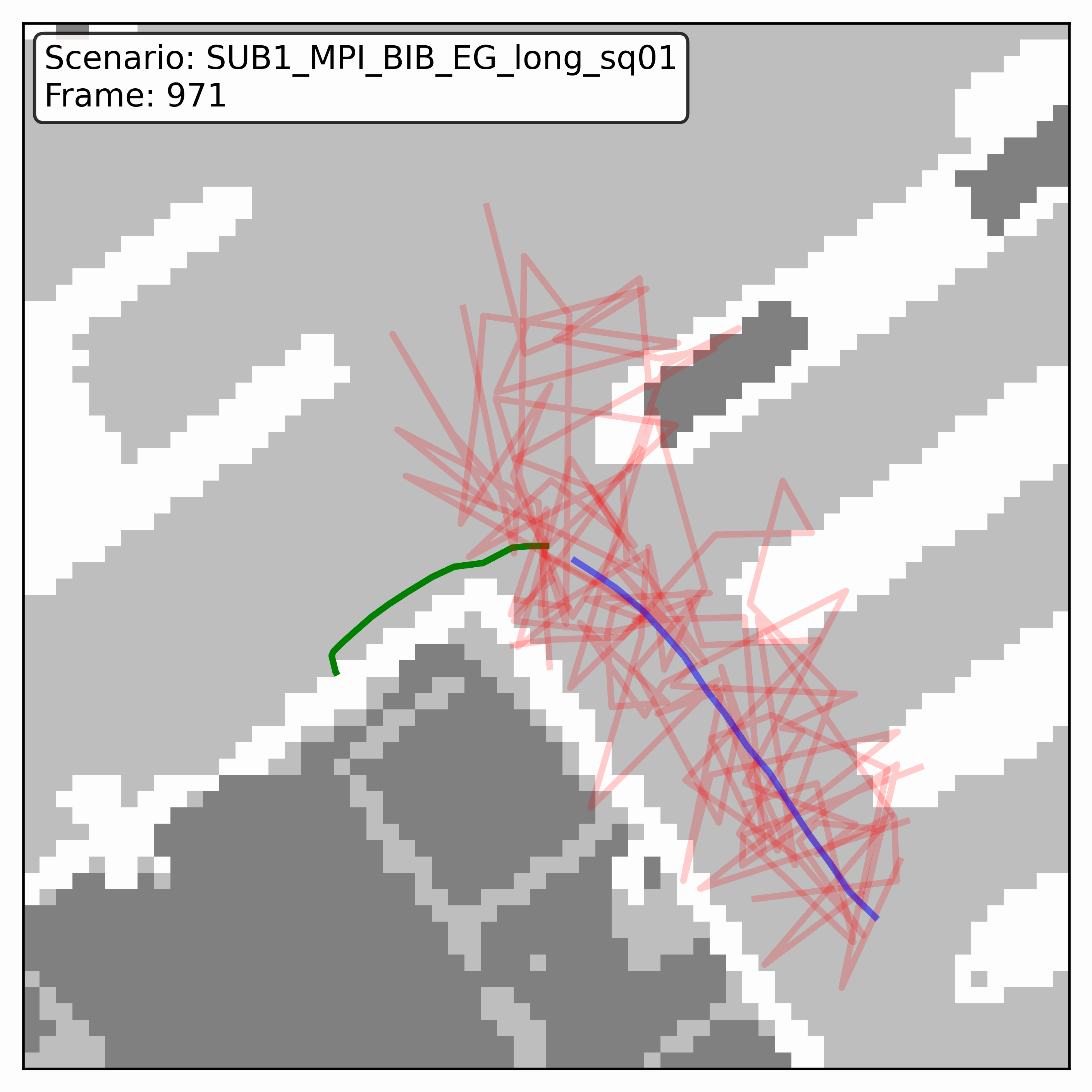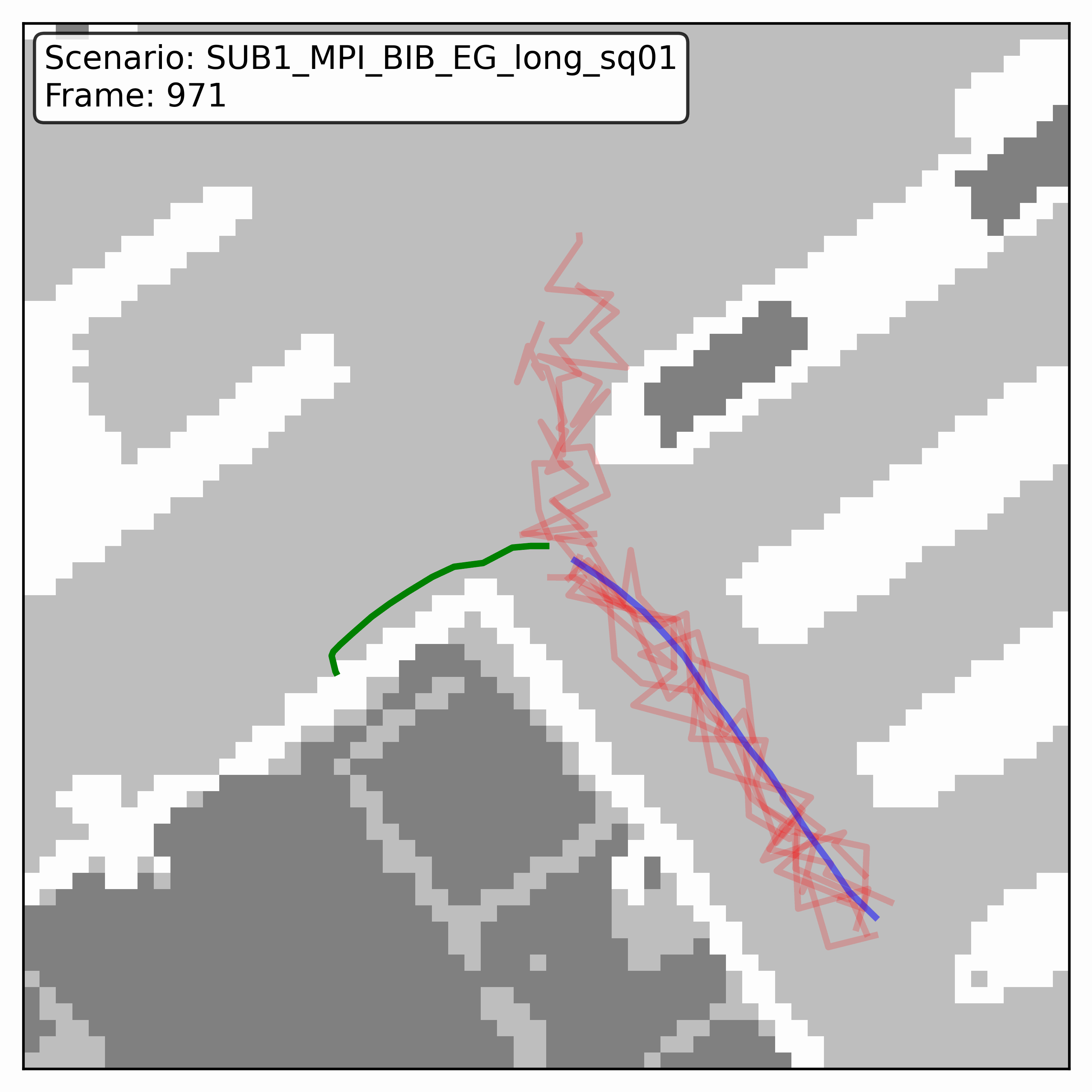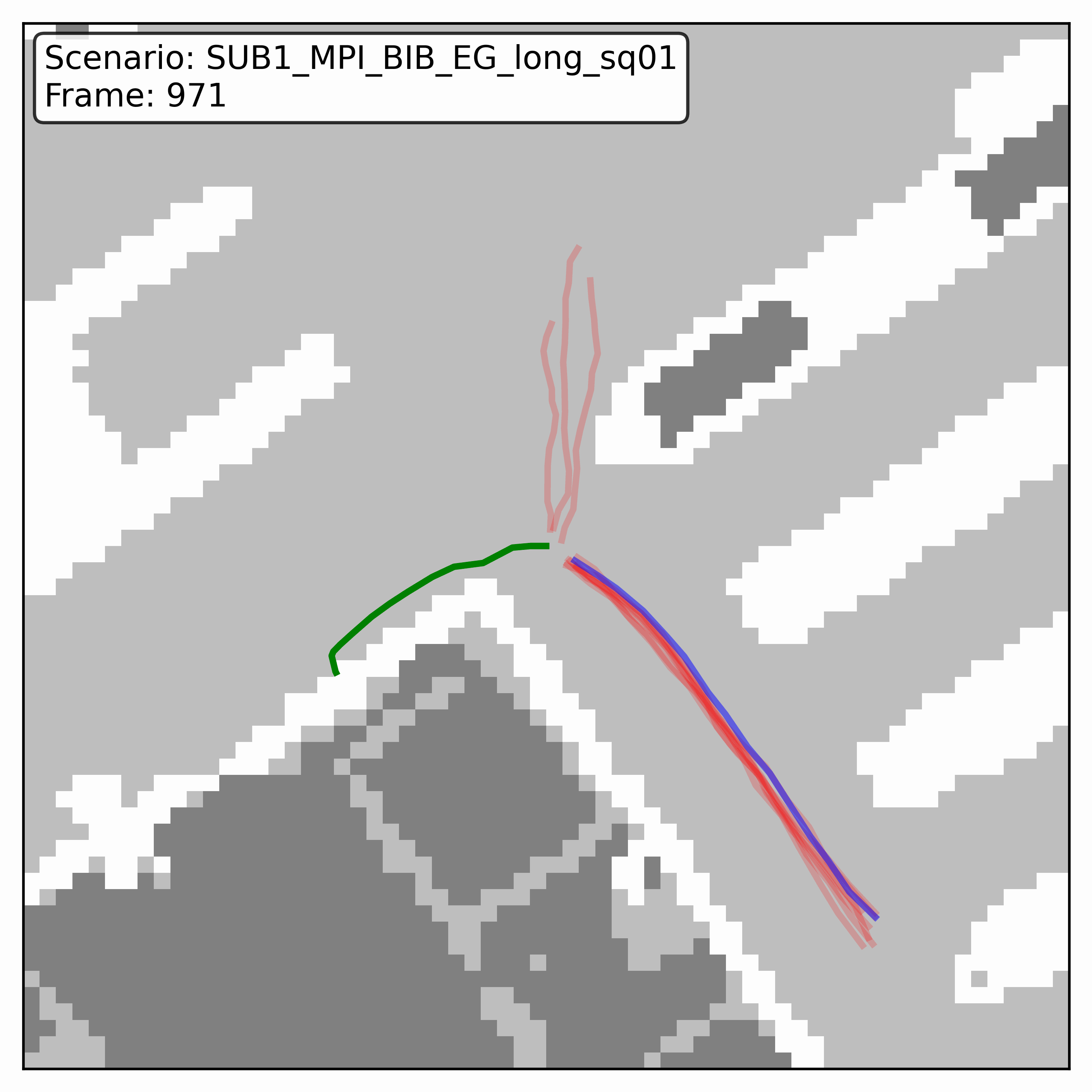
Watching it denoise, at different step counts
Below, motion history is green, the ground truth is blue, and each red streak is one denoising sample converging toward its final prediction — watch the loop. Fewer steps means a shorter, coarser convergence; even at 20 steps (a fifth of full diffusion), the samples still settle onto plausible paths through the scene.
GTA-IM (simulation)
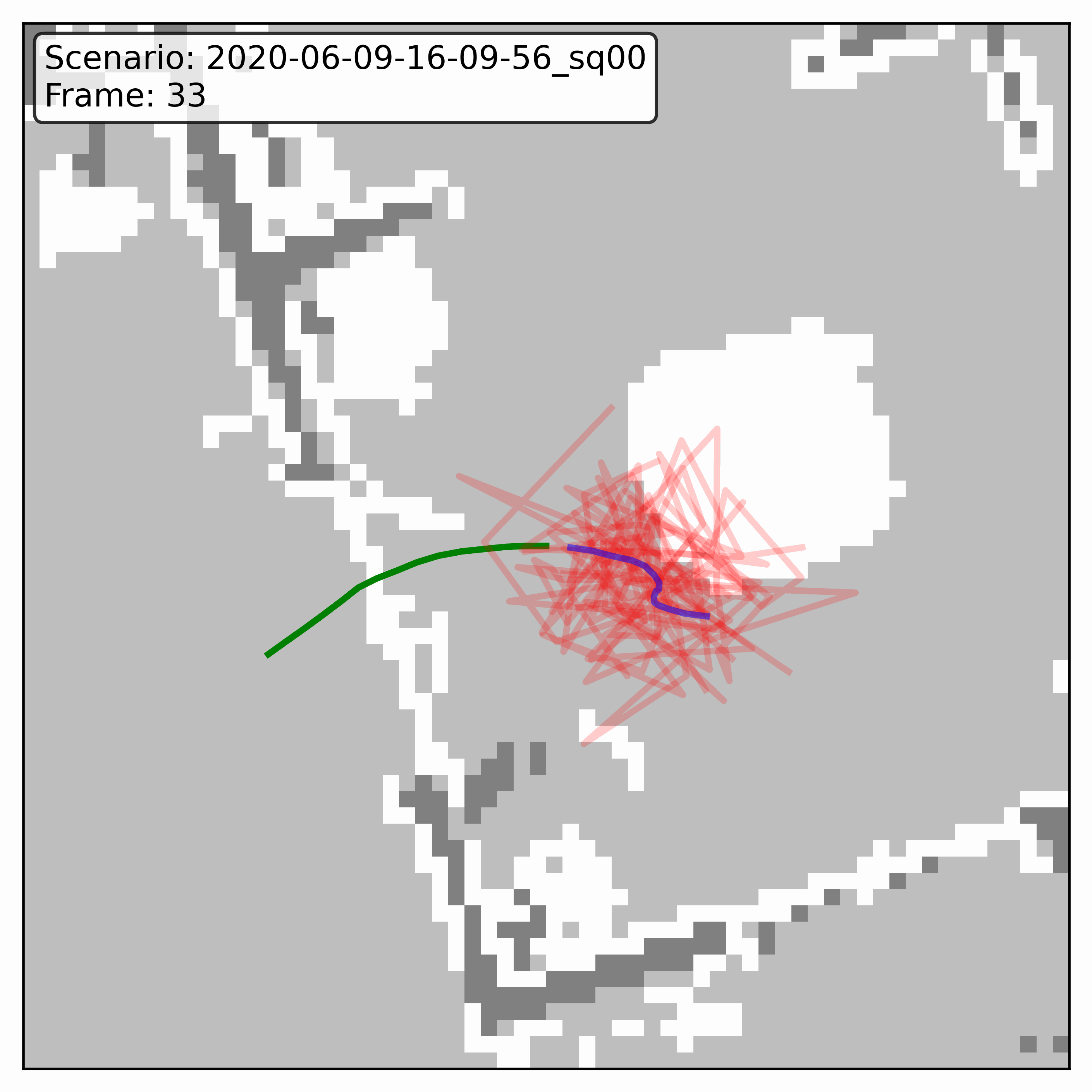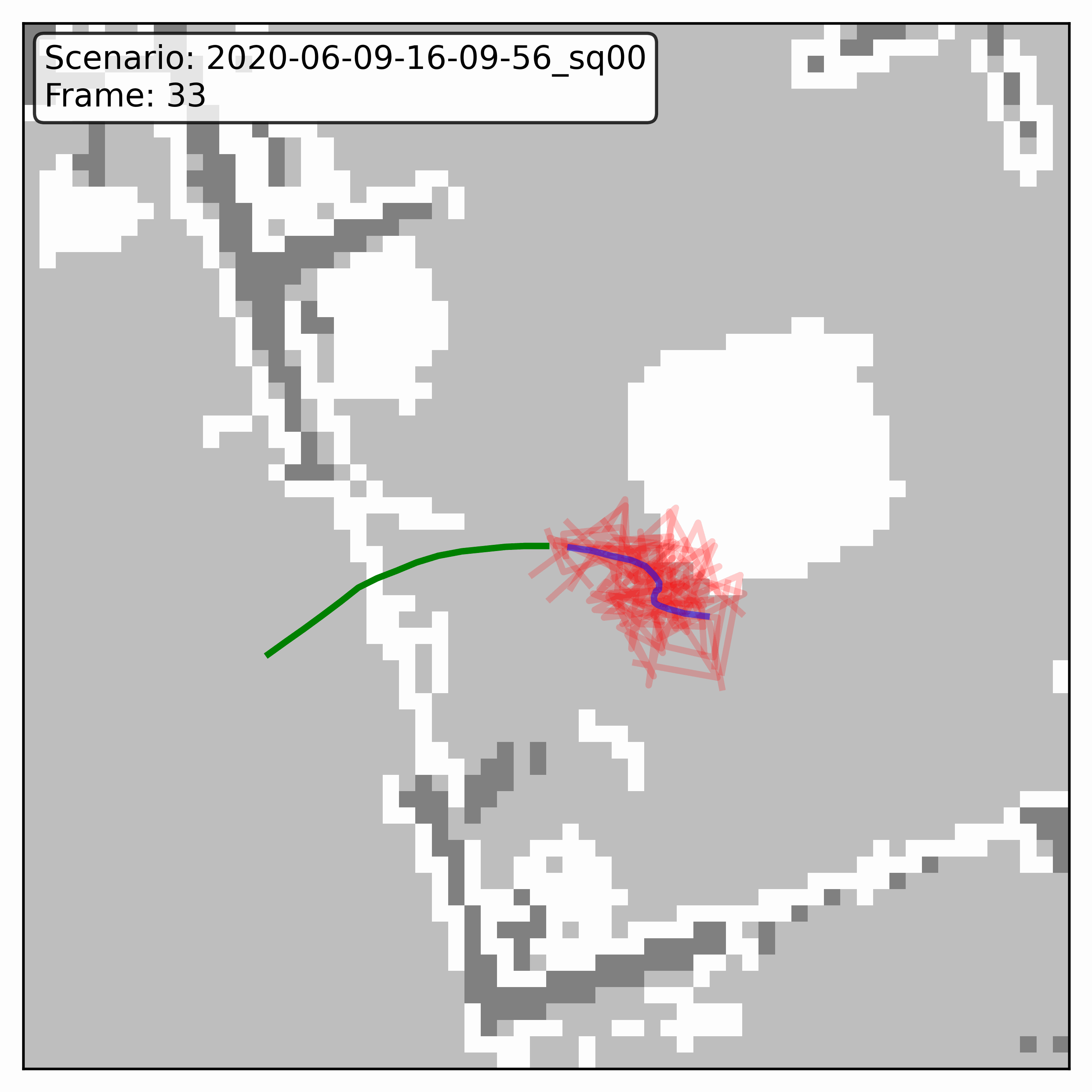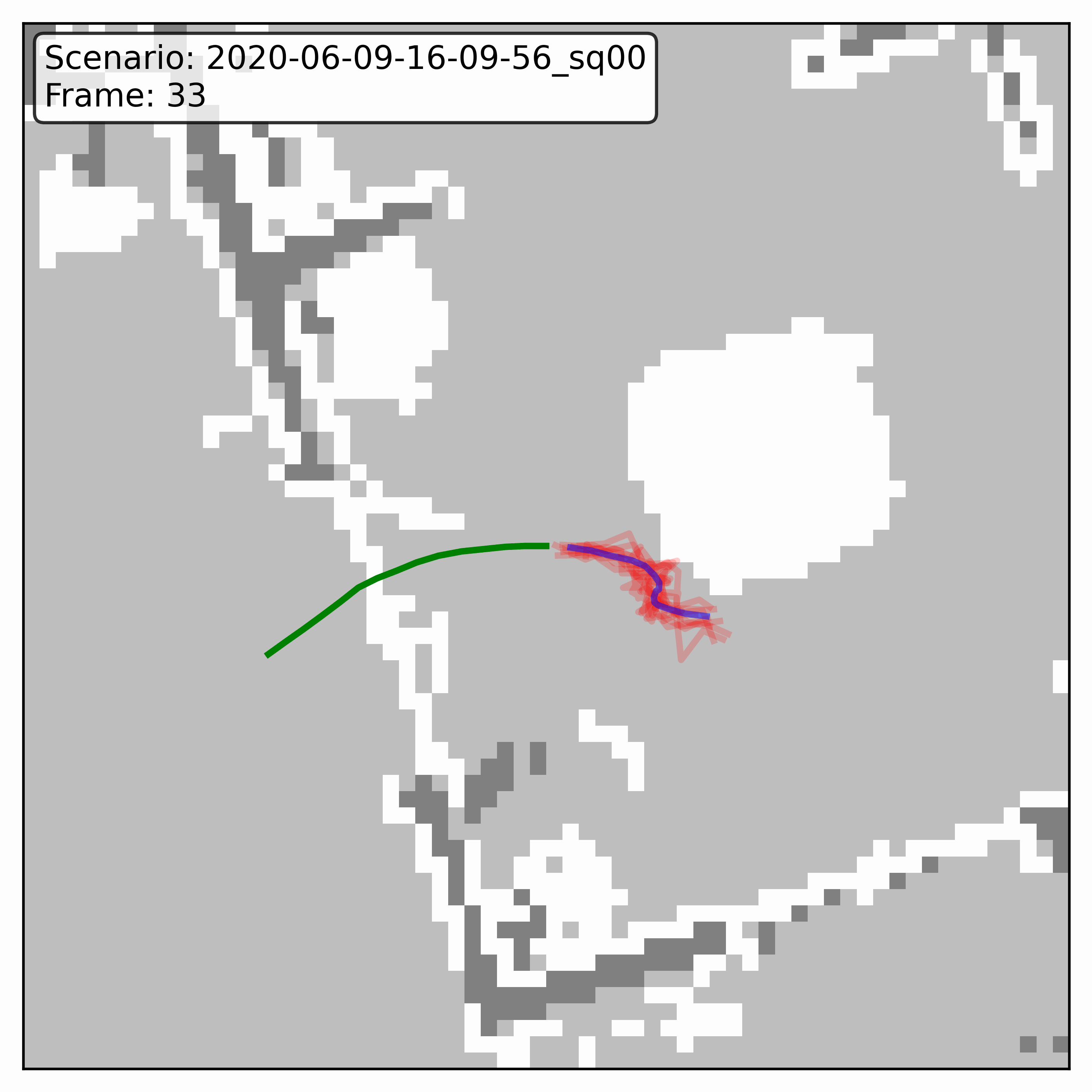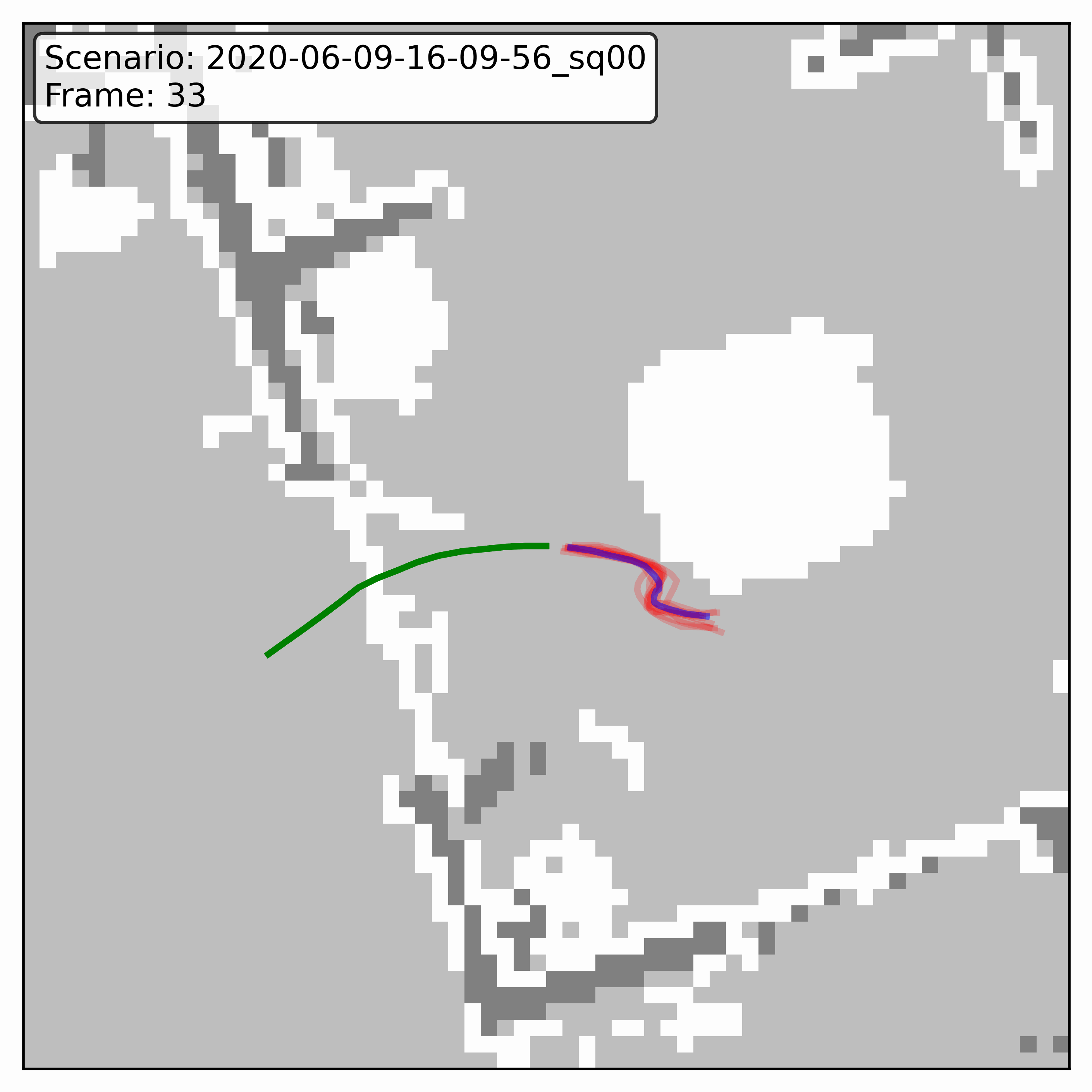
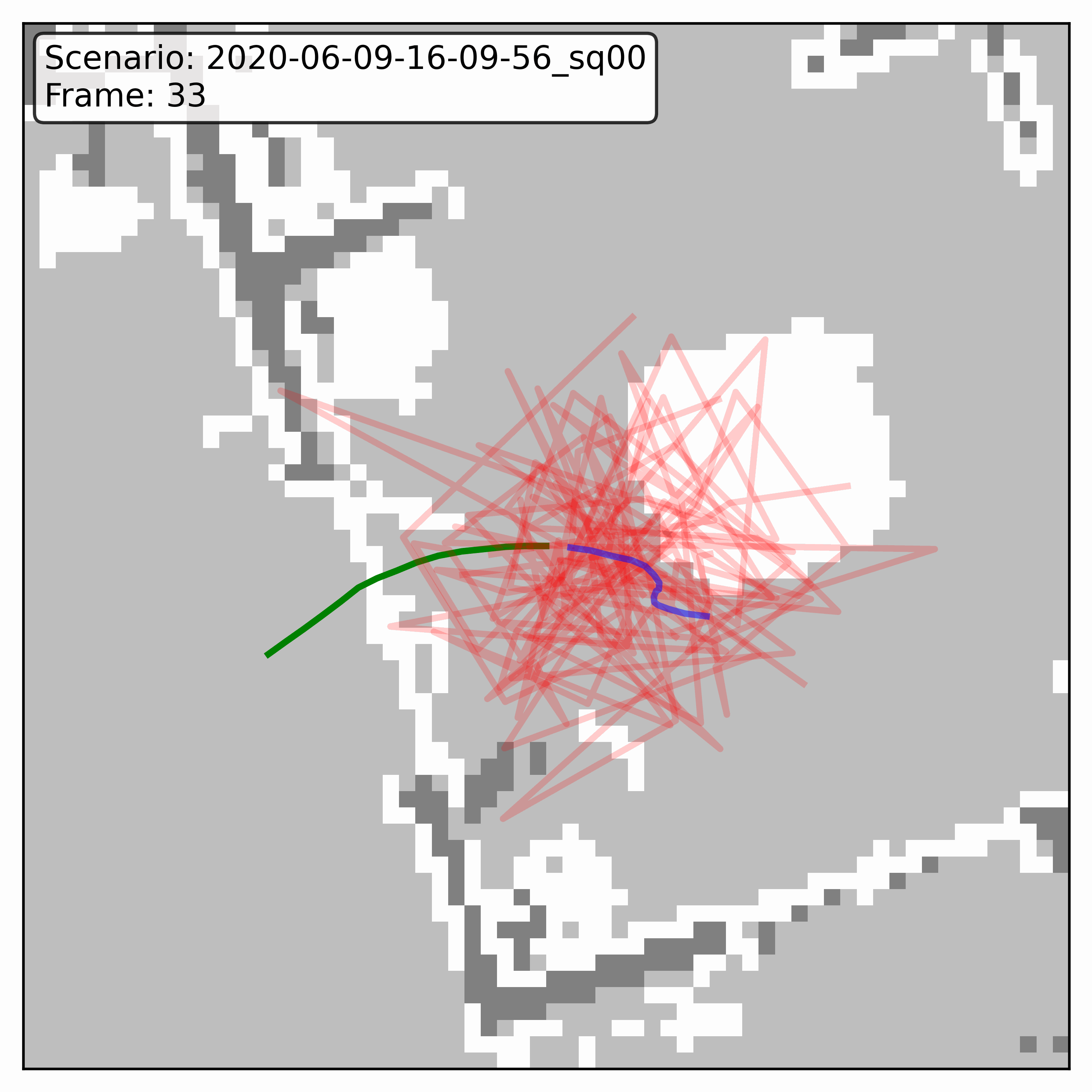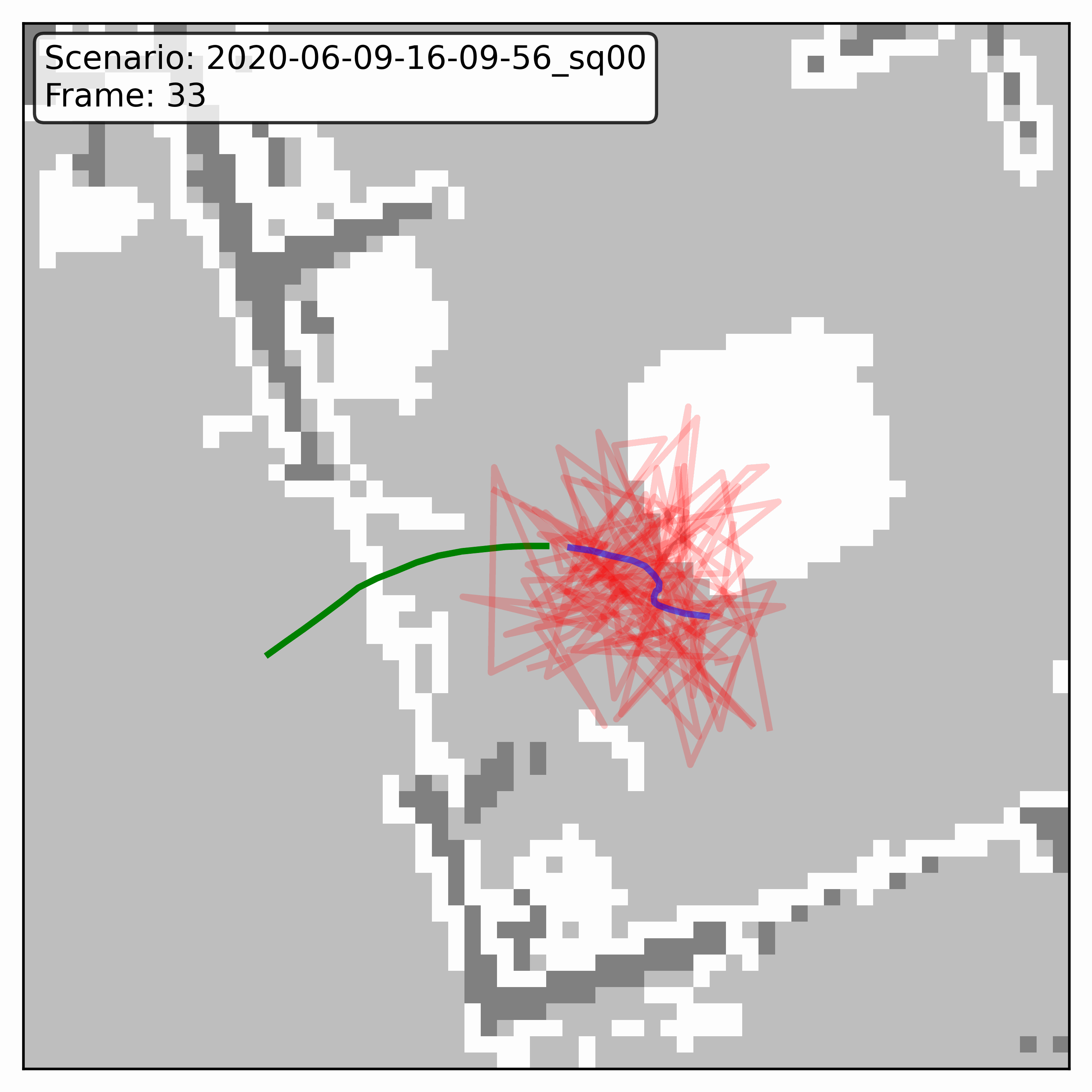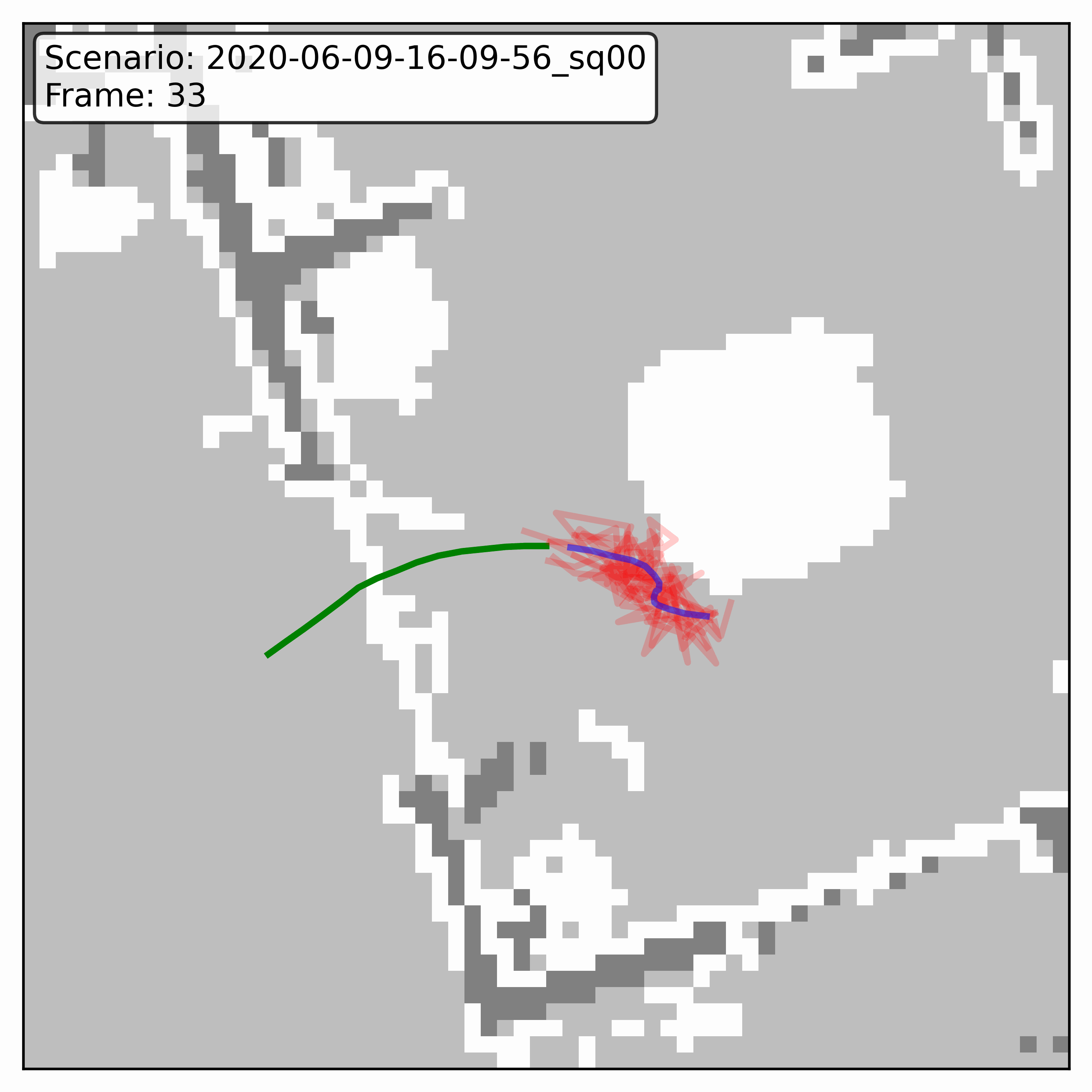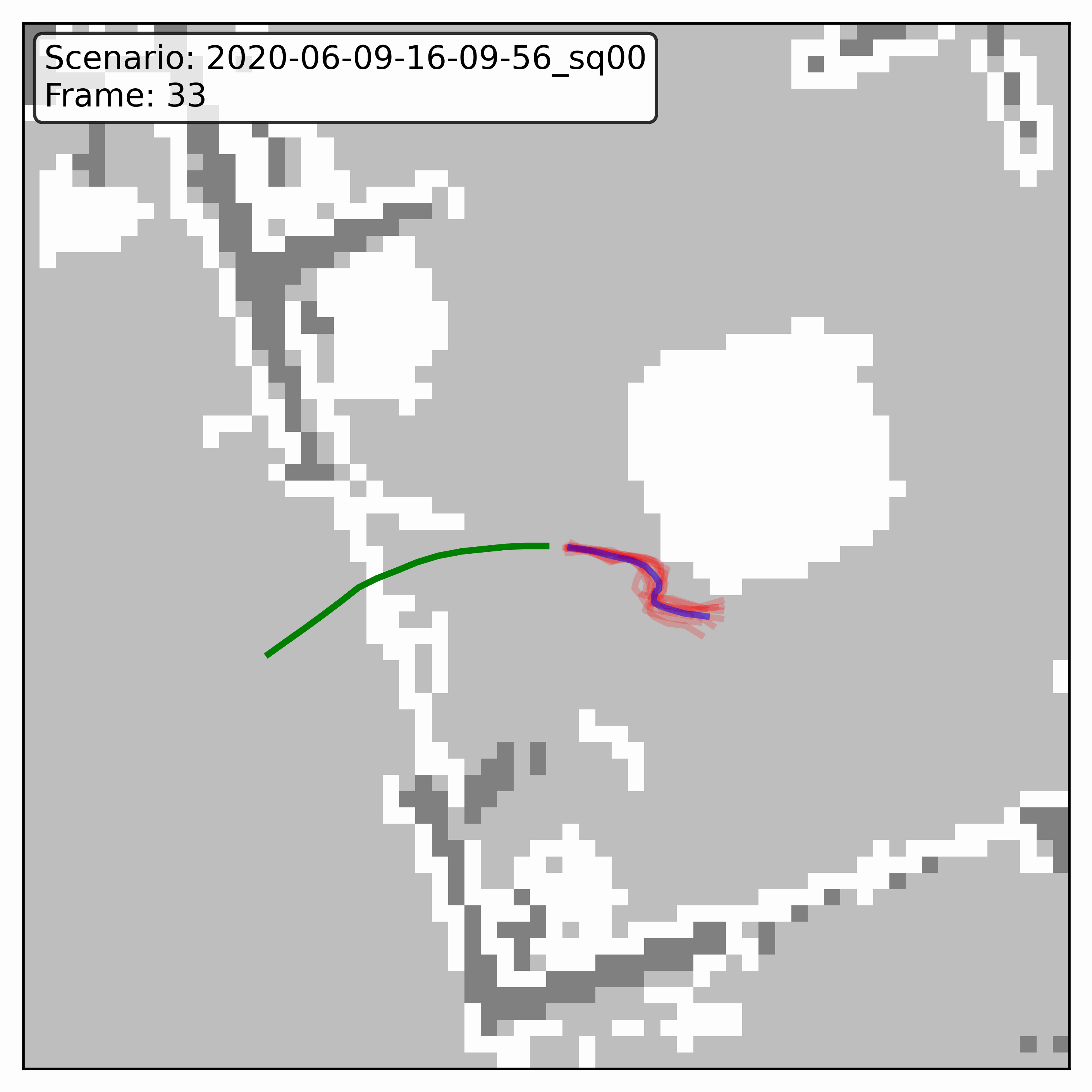
HPS (real world)

Animations from the supplementary material.
Where this breaks — and what's left open
The whole method leans on one assumption: that the world looks roughly the same from one frame to the next, so last frame's samples are still a good prior. When that assumption fails — a sudden turn, a stop, an abrupt change in the scene — the conditioning changes a lot, the theoretical bound loosens, and truncating aggressively stops being safe. In that regime the right move is to fall back toward more denoising steps, up to full diffusion.
We also don't yet have a way to pick the optimal truncation ratio automatically for a given timestep — right now it's a fixed trade-off chosen ahead of time, not something the model adapts on the fly. Working that out is a natural next step.
Final message
Sequential prediction gives you a free prior at every step: what you already believed a moment ago. Reusing it — adding back only as much noise as the change in the world requires — makes diffusion inference significantly faster without giving up its multi-modal predictions, and the amount of speedup you can safely take is something we can actually bound in theory.